Train high accuracy models on large datasets
For best results we recommend training your model on as many documents as possible. The main benefit of training on large datasets is greater overall accuracy. Cradl is built to scale with large datesets, and it is not uncommon to train on millions of documents. Our unique training algorithm makes training on large datasets neither time-consuming nor complicated, and will not have any impact on the processing speed of your final model. If you are already processing documents today, chances are that you have the data needed to train a high accuracy model in Cradl.
Step 1: Download documents with metadata from your database
Goal: Download documents with metadata from your database and transform them to a Cradl compatible format
To train a model in Cradl we need documents and annotations. Each document must have a corresponding
annotation. An annotation is a collection of key-value pairs containing the pieces of information we are teaching the model to extract.
Notice that Cradl does not require you to provide any positional metadata such as bounding box coordinates. We are
only interested in key-value pairs such as total_amount=100.00 or invoice_date=2021-10-30. Annotations are
formatted in JSON. Below is an example of a document and its corresponding annotations.
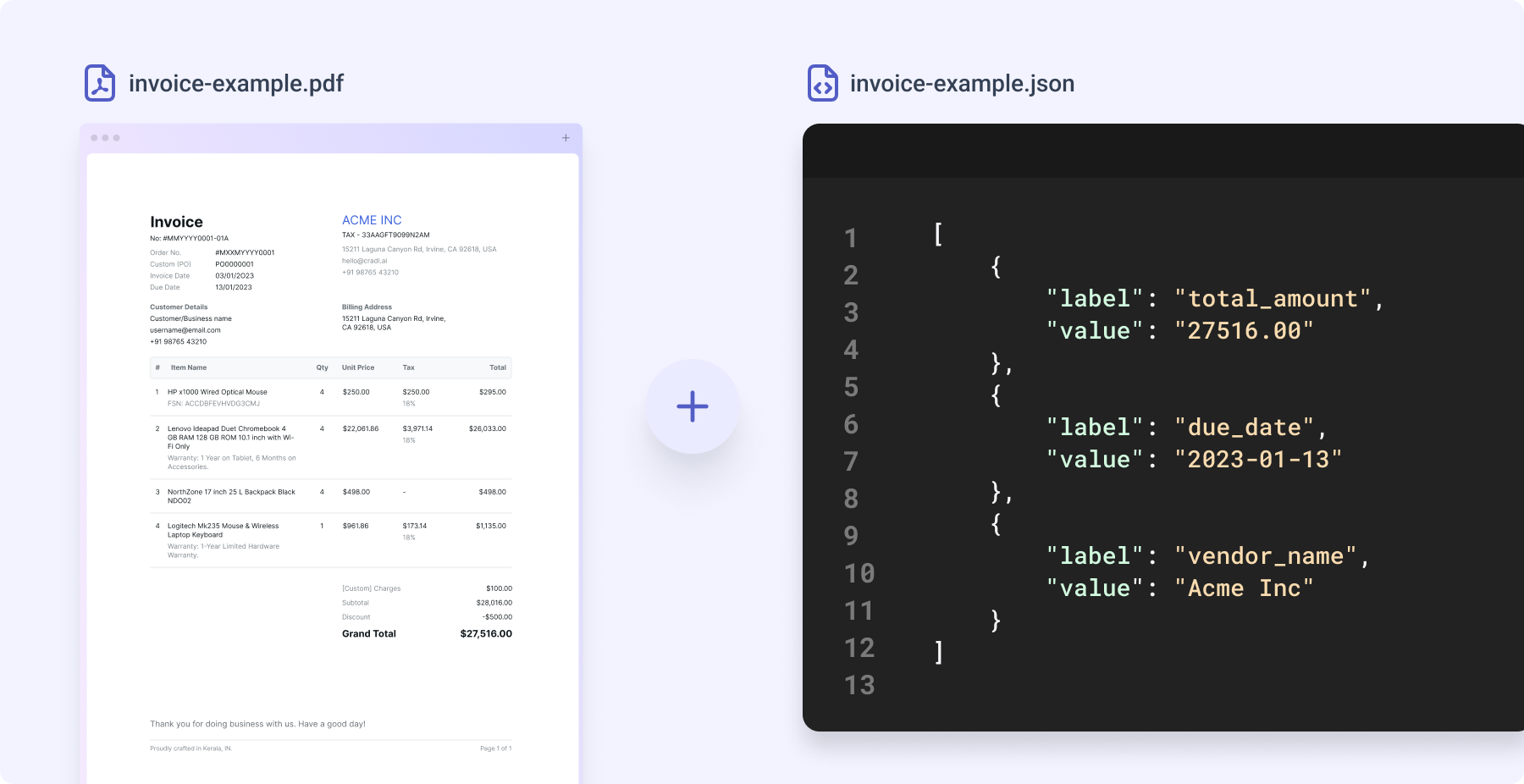
To make the documents and annotations ready for upload in Cradl we need to have all of them in a directory with the following constraint: a document and its annotation file must have the same filename prefix. See the example below.

Having good training data is important in order to get high accuracy. Read more about training data here.
Step 2: Upload data to Cradl
Goal: Upload your documents and annotations to Cradl for training
Before uploading documents and annotations you need to initiate a training job wizard for your model in Cradl. In the upload data step of the training job wizard you can choose between uploading your files directly in the Web UI or using the CLI. We recommend using the Web UI as a way of testing out the training process, and using the CLI when you are ready to train on thousands of documents.
- Using the Web UI
- Using the CLI
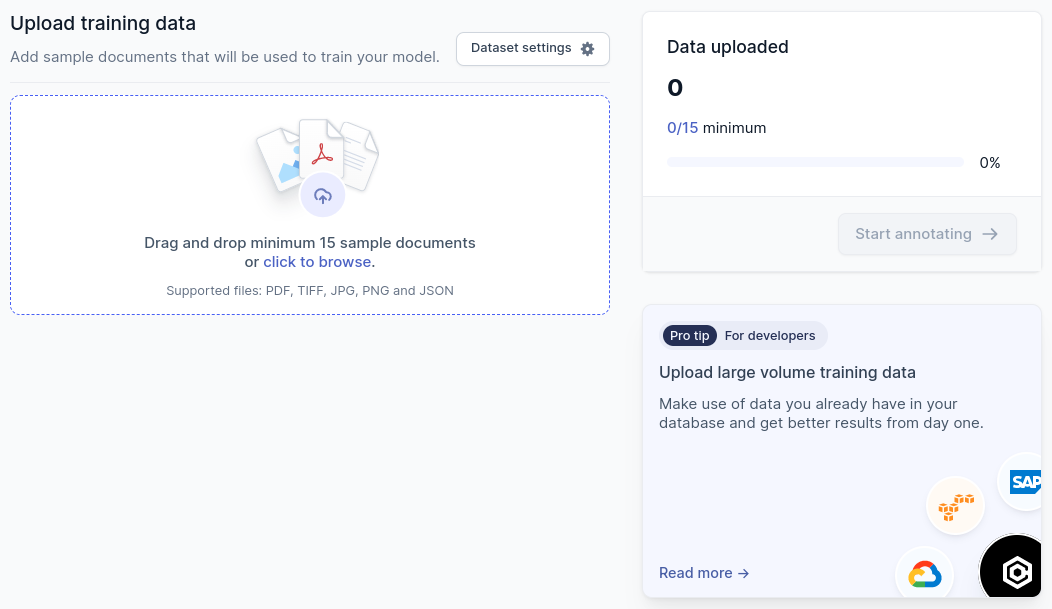
Drag all the files into the drop-zone as shown in below illustration.
You need to have the CLI installed. Follow the instructions here to install the CLI.
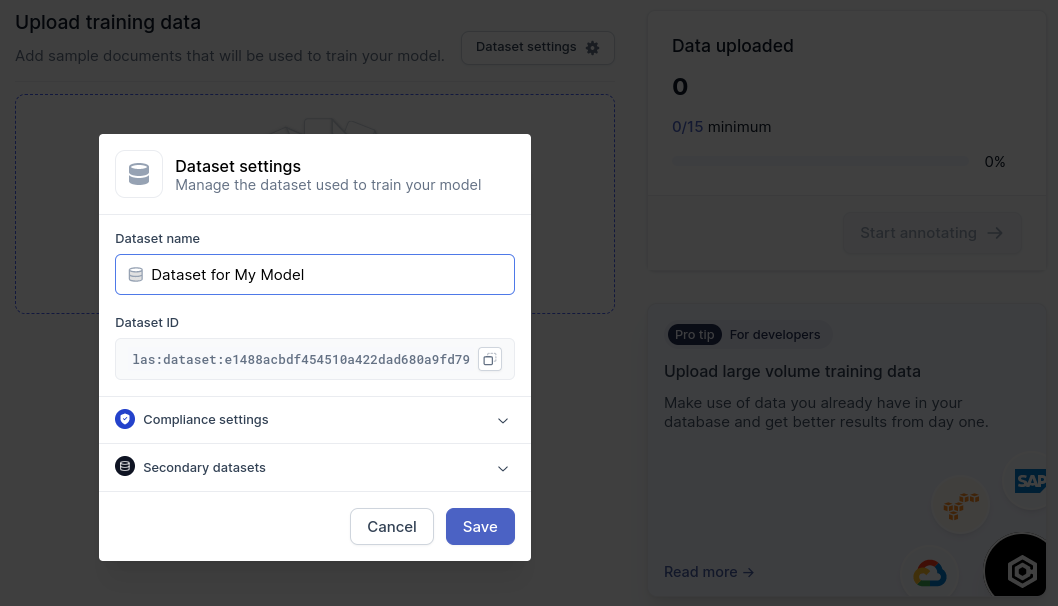
Copy the datasetId from the Web UI as shown in the below illustration.
Then use the CLI to upload documents and annotations from your folder to this dataset.
$ las datasets create-documents <your datasetId> <your folder with documents and annotations>
Step 3: Review your data and start training
Goal: Make sure the data looks alright and start training the model
You should now see the documents you uploaded in the previous step appearing in the Web UI. To proceed, follow the
instructions in the Web UI and you will be taken to a view where you are able to edit or create new annotations for
your documents. If you have already successfully uploaded annotations in the previous step and don't want to add more,
then you probably don't need to do anything here. Proceed to the last step where you will get a statistical overview
of your submitted data. If you are satisfied with the statistical overview, click on the "Start training" button. Your
training should now start shortly. If you submitted more than 1000 documents, one of our data scientists will review
your training before starting just to make sure everything is configured properly and is optimized for your model.
Further reading
Read more about historical data here Read more about the importance of data quality here